 L'Oracle Magazine de Janvier / Février 2007 vient de sortir...
L'Oracle Magazine de Janvier / Février 2007 vient de sortir...... mais si vous ne le recevez pas, c'est le moment de vous abonner à cette publication technique gratuite!
L'Oracle Magazine de Janvier / Février 2007 vient de sortir...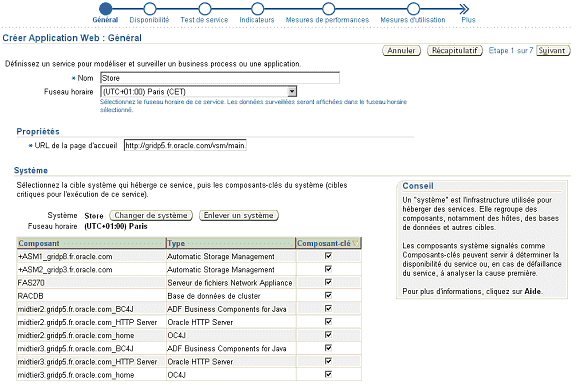

Ce post et les suivants donnent les concepts de l'ASLM avec Oracle Enterprise Manager 10g Grid Control.
(Post précédent : introduction)
Les concepts
1) Notion de « système »
La modélisation du système consiste à créer la vue des composants techniques correspondant au "DataCenter" que l’on veut surveiller ; comme par exemple les bases de données, les serveurs d’applications, la baie de stockage et les composants réseau.
Une fois les composants sélectionnés, la topologie permet de définir la représentation graphique ainsi que les liens d’association entre chacun des composants.
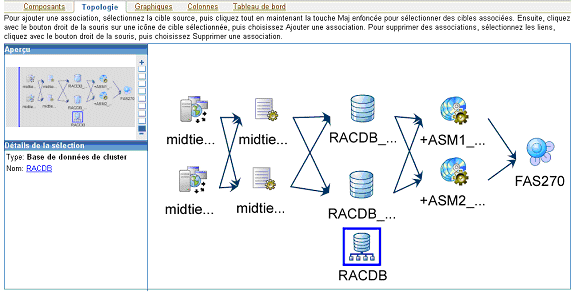
La représentation graphique ainsi obtenue fournit alors une vue claire et détaillée de l’ensemble des composants techniques impliqués; ce qui est extrêmement utile pour identifier l’état des composants !
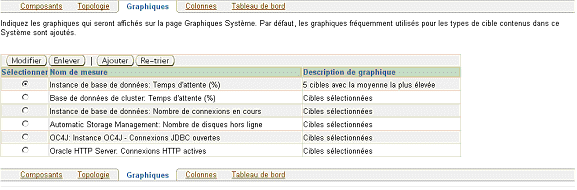
Lors de la définition d’un système, une étape consiste à sélectionner les mesures par composants que l’on désire voir afficher dans les performances du systèmes.
Pour chacun des composants, de nombreuses mesures sont disponibles, donnant ainsi des informations très détaillées sur les éléments.
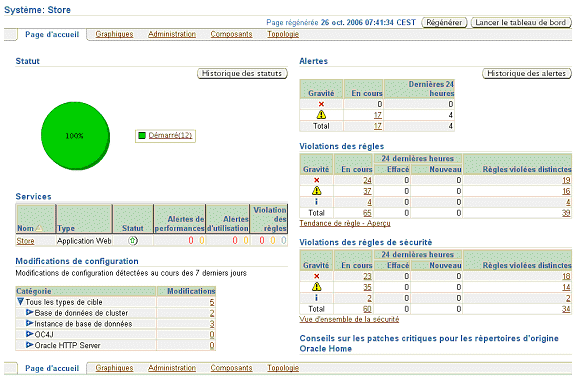
Une fois le système modélisé, l’administrateur obtient une vue synthétique agrégée de l’ensemble des composants, évitant ainsi une surveillance composant par composant !
L’administrateur a ainsi à sa disposition l’ensemble des alertes, avertissements, les règles et les arrêts planifiés (blackout) ainsi que l’historique des statuts et des alertes.
L’accès aux tableaux des modification de configuration permet de suivre l’évolution et de suivre l’ensemble des modifications effectuées au cours du temps et ainsi éventuellement de revenir "en arrière" en cas de problème.
L’administrateur suit aussi les différents services qui utilisent ce système ; permettant ainsi de faire rapidement le liens entre les incidents système et ceux applicatifs.
La console lui permet de gérer des scripts pour l’ensemble des composants et de suivre l’activité des travaux ainsi programmés.
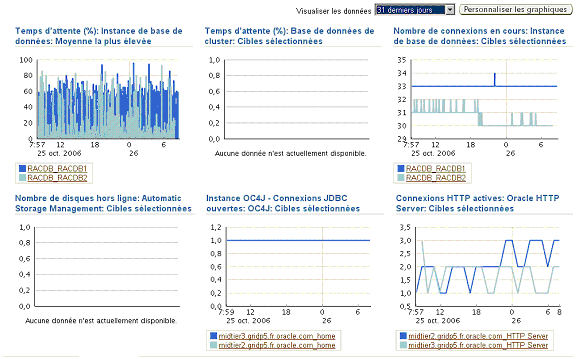
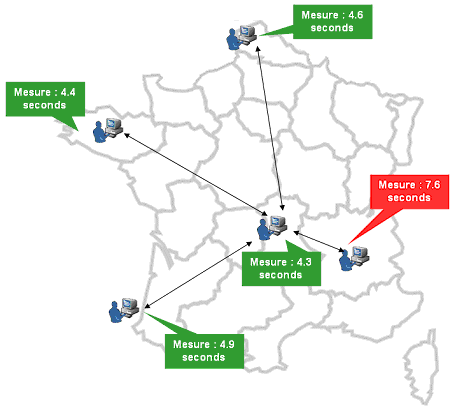
Les mesures sélectionnées lors de la modélisation du système sont présentées sur la page des graphiques.
Il est donc très important de prendre les informations les plus pertinentes et de ne pas trop mettre de mesures afin que cette page ne devienne pas l’équivalent du tableau de bord d’une navette spatiale !
Le tableau de bord présente une synthèse de l’état du système. Les administrateurs peuvent personnaliser les colonnes à afficher ; par défaut : cible, type, statut, alertes, violations de règles, score de conformité et temps d’attente. L’ensemble des mesures disponibles pour chacun des composants du système peuvent être sélectionnées ; par exemple nombre de transaction par seconde, session actives en attente, connexions JDBC ouvertes, demandes par secondes, connexions HTTP actives, total E/S réseau, …
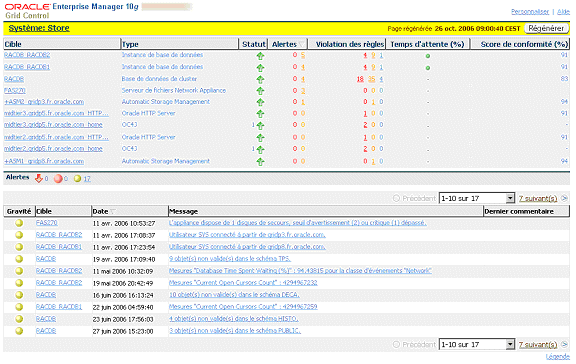
Comme précédemment, il est nécessaire de choisir des mesures intéressantes pour la surveillance du système et de ne pas transformer les tableaux blanc en cockpit !
A suivre ...
(Post précédent : introduction)
Problématique
Aujourd’hui, la plupart des applications sont en mode Web et nécessitent rapidité d’exécution et disponibilité. Les utilisateurs se sont habitués à des temps de réponse "extrêmement rapide" , pratiquement instantanés ; ce qui fait que dans les cas où ils rencontrent des pages "plus" lentes, ils ont tendance à "s’agacer" voir même chercher un site web assurant la même prestation.
Dans le cas d’une application internet stratégique, telle qu’une application de commerce électronique, ce comportement à un impact sur le business : le client ne commande pas et de plus risque de partir à la concurrence voire même ne plus revenir à l’avenir !
De ce fait, ces applications vont nécessiter un niveau service élevé, aussi bien en terme de disponibilité que de performance.
Besoins
Composé de matériel, OS et logiciels hétérogènes, le système d’information devient de plus en plus complexe et ce malgré les efforts de consolidation.
D’un côté, comme nous l’avons vu, les utilisateurs demandent de plus en plus aux applications, en matières de temps de réponse et de sécurité.
De l’autre, les administrateurs du système d’information sont confrontés à la gestion d’une plate-forme hétérogène ; c’est-à-dire qu’il leur faut réagir aux problèmes d’arrêt et de perte de performance de la chaîne applicative dans sa globalité et non composant par composant.
Hors cette chaîne applicative peut être constituées d’éléments complètement différents.
On peut très vite se retrouver avec des environnements complexes à surveiller, en terme de composant, de logiciels mais aussi d’OS et de hardware.
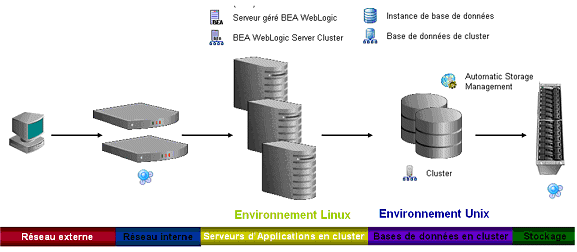
La question de pose de connaître la qualité de service de la chaîne applicative et des composants techniques sous jacent, cela permettant de pouvoir corréler les évènements fonctionnels et techniques.
Les utilisateurs notent un ralentissement de l’application, il faut trouver rapidement le ou les points de ralentissement voir les composants en arrêt sans avoir à passer par les fichiers de log des différents composants de la chaîne.
Ce qu’il faut à l’administrateur du système d’information est une console capable de fournir une vue logique agrégée de l’application et des composants techniques impliqués, permettant ainsi de répondre rapidement aux différents problèmes rencontrés : on parle de diagnostic de bout en bout de la chaîne applicative.
Mais cela ne suffit pas !
Il faut aussi fournir un mécanisme capable de prévenir les administrateurs ; passer ainsi d’un mode d’attente à un mode d’informations proactives. On parlera de Root Cause Analysis ; identifier rapidement et facilement les points de ralentissement ou d’arrêt.
Nous venons d’introduire les concepts de SLM (Service Level Management) ou ASLM (Application Service Level Management); capacité à gérer la qualité de service d’une chaîne applicative.
A suivre ...

 L'Oracle Magazine de Novembre / Décembre 2006 est disponible.
L'Oracle Magazine de Novembre / Décembre 2006 est disponible.